Safe continuous deployment with automated end-to-end tests
From commit to production, learn how to continuously deploy your application while maintaining high reliability and minimizing risks.

Continuous deployments do not have to be risky. In fact, by automating your delivery pipeline with end-to-end tests and alerts, you will be able to deploy faster and with more confidence while saving engineering time, what’s not to like?
The case for continuous delivery
For most web applications, it is considered a best practice to continuously deliver changes to production and for good reasons:
- It allows you to ship features faster and resolve critical bugs in shorter time.
- With smaller changes being released independently, you can quickly identify the root cause should you introduce a regression.
- It reduces the impact of your rollbacks, thus mitigating the risks associated with larger features delivery.
Requirements for safe continuous delivery
While it is easy to achieve in practice: deploy your commits to production as soon as they are merged into your main branch, there are a few fundamental requirements you need to meet in order to do that in a safe, reliable way:
- Your application can be deployed as an atomic unit: it is a single unit that can be deployed independently.
- Your delivery pipeline is idempotent: it can be deployed multiple times without side effects and will always end up in the same state.
- It is easy to rollback to a previous version if something goes wrong.
Typically for web projects, that means using a package manager lockfile and a delivery script without side effects aside from bumping a release version.
It is also important to have some form of monitoring and alerting in order to be quickly notified when things are not working as expected on production. I will dive deeper into this topic in a subsequent post.
The safe delivery blueprint
In practice, the blueprint is simple: deploy your application to a preview environment and run simple end-to-end tests to make sure your final application state is accessible and covering your critical user flows before promoting it to production. There is not much more to it.
Yes you should also run those end-to-end tests on your pull requests before actually merging them to your main branch but your main branch is the real deal and I have seen too many incidents where things went wrong in production because the release deployed was never tested in its final state.
Here is a diagram of the blueprint:
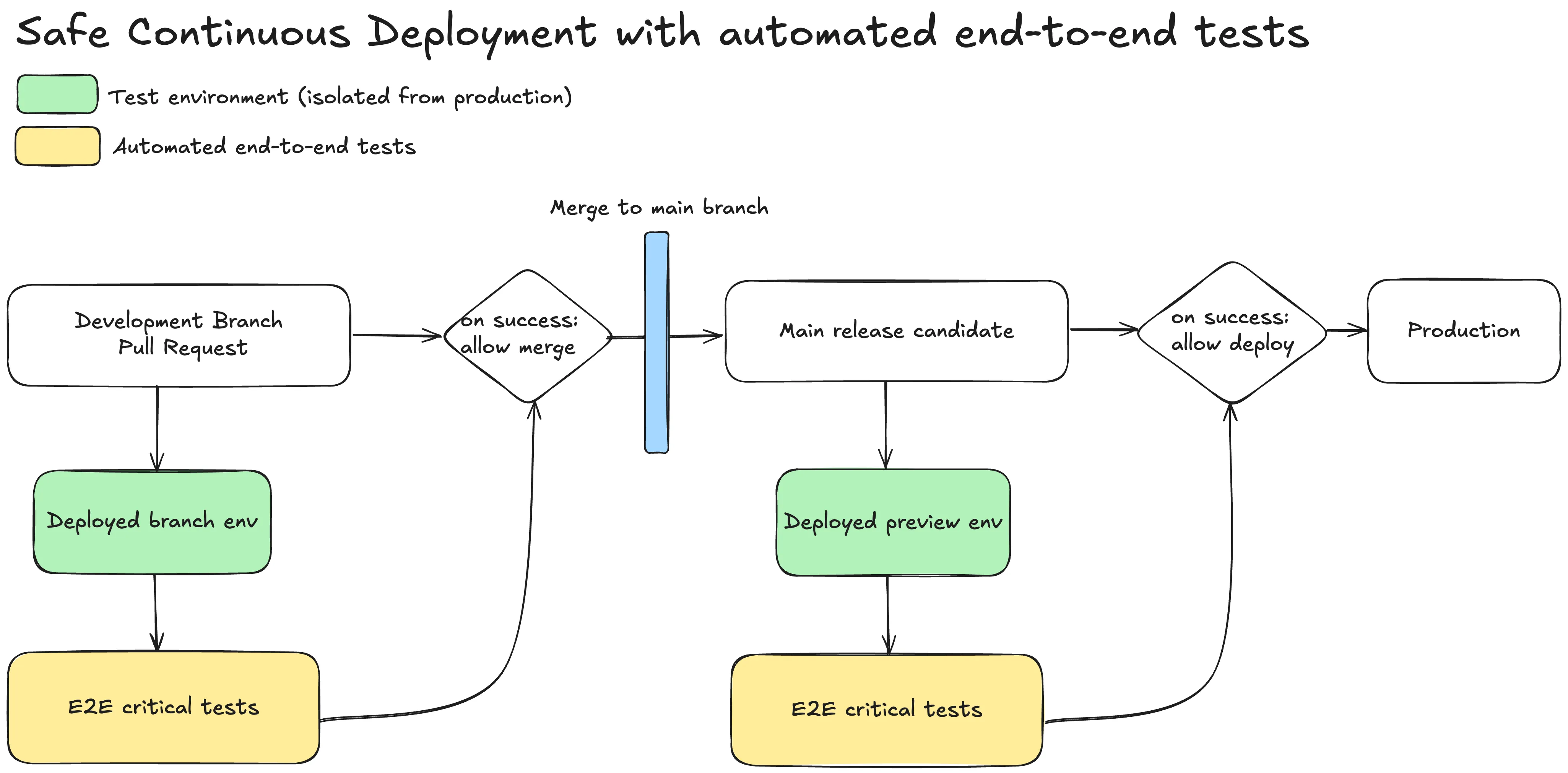
Concrete example with Github Actions
While this example is based on Github Actions, the same principle apply to any CI/CD solution coupled with any deployment strategy. Here is an overview of a the blueprint solution:
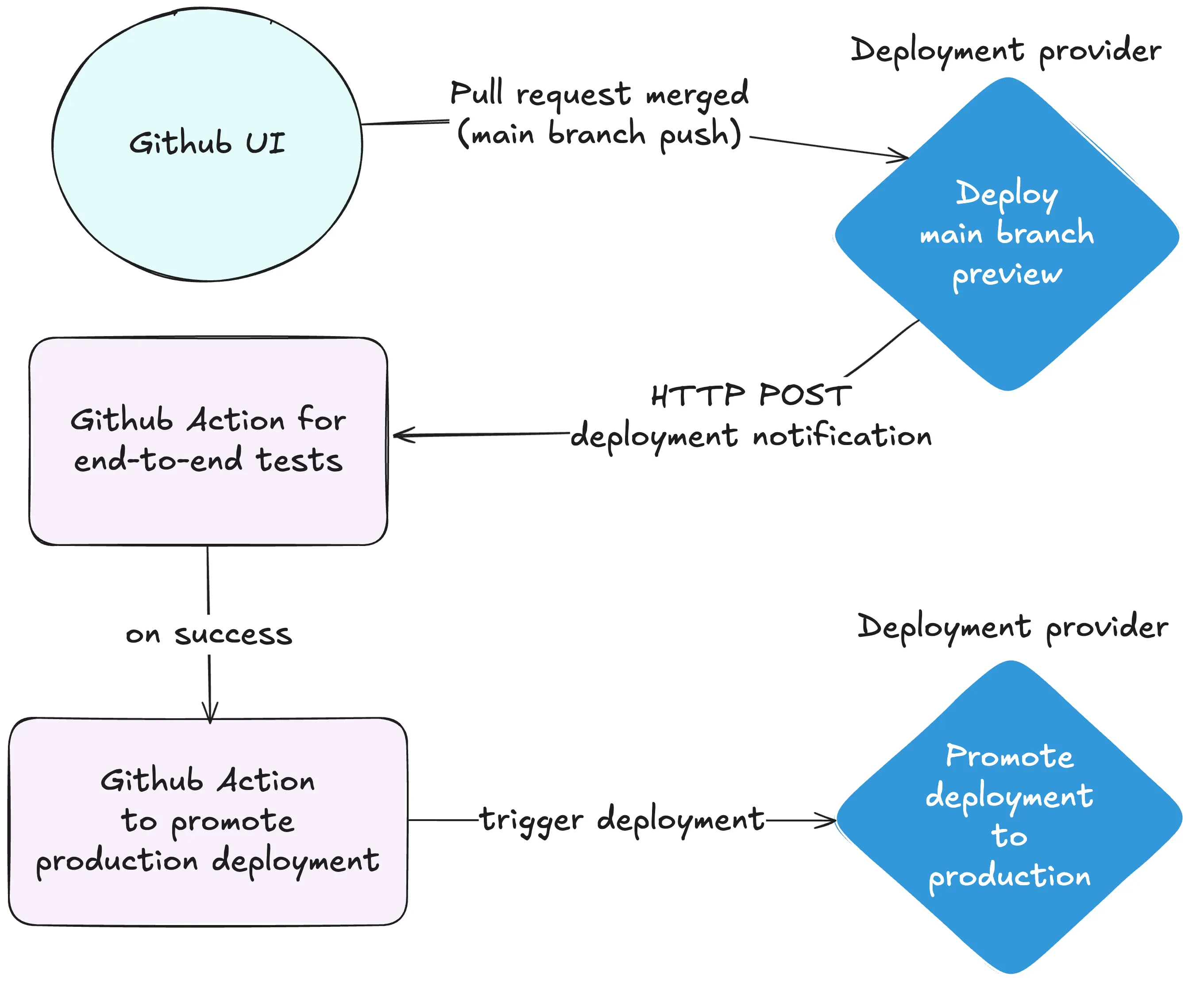
I created end-to-end guides to deploy safely with Vercel and Netlify that you can follow to get started and I have a demo repository containing full code examples as it is configured to be deployed both to Vercel and Netlify.
Implementing the blueprint
If you are not yet deploying automatically to production, chances are that you are running manual tests before and after deploying as well as monitoring your application during the deployment.
This is the final important step to achieve a safe continuous deployment workflow: you need to have a minimum level of monitoring and alerting in place to be notified when something goes wrong as you will no longer monitor manually.
You can start simple here: set up email or chat notifications based on an error threshold. If you are using Application Monitoring Tools like Sentry, it is easy to get started with alerts for example. Ideally you also have some analytics solution in place but from experience the feedback loop with these is too long to react quickly enough to issues created by your deployments.
If you’ve successfully implemented the blueprint, I would love to hear your feedback and if you have any questions, feel free to reach out.